
Sommaire
Le contenu dupliqué (alias duplicate content) non géré est, à mon avis, l'un des problèmes d'optimisation des moteurs de recherche les plus préjudiciables pour un site Web, avec le potentiel d'avoir un impact significatif sur vos classements et vos performances organiques.
Si vous êtes impliqué dans le marketing numérique depuis un certain temps, vous avez très probablement entendu parler du “contenu dupliqué”, peut-être par les équipes SEO de votre entreprise, les spécialistes du marketing de contenu ou les agences SEO partenaires. Il se peut également que vous ayez écouté une explication et que vous ayez l'impression d'avoir une compréhension de base de ce que le contenu dupliqué implique.
Au cours des dernières années, j'ai lu, regardé et entendu une pléthore d'explications différentes sur le contenu dupliqué ; des forums SEO aux messages sur les médias sociaux, et même des articles de blog d'agences professionnelles. Il existe de nombreux cas – en particulier depuis 2013 – où des sites ont été lancés avec des problèmes qui n'ont jamais été identifiés, et par conséquent n'ont jamais atteint leur potentiel. En conséquence, je ne peux m'empêcher de penser que beaucoup de gens (y compris les référenceurs professionnels) ne comprennent pas bien ce qu'est le contenu dupliqué et comment il peut avoir un impact sur votre présence en ligne.
Étant donné l'impact potentiel, il est surprenant qu'il y ait autant de désinformation sur ce qu'est le duplicate content et sur comment le résoudre. Dans cet article, je vais vous expliquer :
- Ce qu'est le contenu dupliqué ?
- Comment le contenu dupliqué se produit-il ?
- Comment gérer le contenu dupliqué ?
Qu'est-ce que le contenu dupliqué ?
“Votre site web semble contenir de grandes quantités de contenu dupliqué”.
“Mais nous avons écrit tout le contenu nous-mêmes ! ?”
Le premier obstacle à franchir est la langue ; le plus souvent, les gens associent le contenu dupliqué au plagiat. Ce n'est pas le cas.
Il existe deux catégories de contenu dupliqué :
- le contenu dupliqué interne (on-site)
- le contenu dupliqué externe (off-site)
Des parallèles peuvent être établis entre les problèmes de contenu dupliqué off-site et le plagiat, bien qu'il ne s'agisse pas d'un problème technique que vous pouvez contrôler.
Les causes, les impacts et les solutions associés à chaque type sont entièrement différents, et croyez-moi, le contenu dupliqué interne est la pire des situations ! C'est cette catégorie que je vais aborder dans ce guide.
Selon ma définition (que j'ai pu la lire quelque part ou inventer), le “contenu dupliqué interne” est un problème de SEO technique, causé par la façon dont un site Web est conçu. Il se produit lorsqu'une page Web spécifique est affichée sur plusieurs URL différentes. Il ne s'agit pas d'un contenu qui a été volé, réutilisé ou pris à d'autres endroits sur le Web ou sur votre site Web.

Vous savez donc que presque tous les sites Web pilotés par un système de gestion de contenu (CMS) produisent du contenu dupliqué – la question est de savoir s'il est géré correctement ou non.
L'exemple le plus simple est votre page d'accueil. Une page d'accueil peut s'afficher lorsque vous tapez exemple.com ou www.example.com. Dans ce cas, le même contenu est rendu sur deux URL différentes, ce qui signifie que l'une d'entre elles est un duplicata de l'autre.
Ce n'est un problème que si les moteurs de recherche sont capables d'explorer les doublons. Cela dit, ne sous-estimez jamais la capacité d'un Googlebot à trouver des choses. Il dispose généralement d'un coup de pouce, comme un plan de site XML (ou HTML) ou un lien CMS mal configuré. Lorsque Google vous envoie plus de 50 % de vos clients en ligne, cela vaut la peine de prendre des précautions.
Alors pourquoi s'inquiéter face au contenu dupliqué interne ?
Ne vous inquiétez pas, mais soyez-en conscient. L'index de Google est entièrement basé sur les URL. Lorsque la même page est rendue par deux URL différentes, il n'y a aucune indication claire quant à la page correcte. Par conséquent, aucune des deux pages ne se classe aussi bien qu'elle le devrait dans les SERPs.
En outre, en mai 2012, parmi une série de mises à jour, Google a inclus des pénalités plus sévères pour le contenu dupliqué dans le cadre de sa mise à jour Panda 3.4. J'ai eu la chance de travailler sur un site à l'époque qui a été fortement pénalisé suite à la mise à jour, et j'ai rapidement appris à gérer les pénalités liées au contenu dupliqué.
Il est utile de mentionner à ce stade que, contrairement aux pénalités de liens de Pingouin, les pénalités de contenu dupliqué peuvent être supprimées très rapidement en prenant les bonnes mesures. D'après mon expérience, vous n'avez pas besoin d'attendre une mise à jour de Panda.
Les signes de contenu dupliqué
Le contenu dupliqué peut apparaître dans un certain nombre de cas, mais il se produit le plus souvent au moment d'une mise à jour Panda, après le lancement d'un nouveau site Web ou lors de modifications apportées à un site où la gestion du contenu dupliqué a été mise en œuvre de manière incorrecte (ou pas du tout). Les classements et le trafic commencent à baisser, mais l'impact dépend de la gravité du problème.
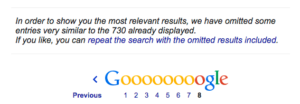
Si vous avez une bonne connaissance du contenu dupliqué, vous serez en mesure de le trouver en effectuant des contrôles manuels sur un site, mais pour une vérification rapide, vous pouvez effectuer une recherche de site dans Google (site:votredomaine.com). Si vous voyez le message suivant sur la dernière page des résultats de recherche, il est possible que le contenu soit dupliqué. Vous devrez approfondir votre recherche pour en être certain.
Comment se produit le duplicate content ?
Duplicata de page d'accueil
Comme je l'ai mentionné au début, l'un des cas les plus courants de contenu dupliqué sur chaque site Web est la duplication entre le sous-domaine www et le domaine racine non-www.
Par exemple :
- www.example.com
- exemple.com
En fonction de votre serveur, vous constaterez que la page d'accueil peut également être affichée à l'adresse suivante :
- exemple.com/index.php (serveurs linux)
- www.example.com/index.php (serveurs linux)
- exemple.com/home.aspx (serveurs windows)
- www.example.com/home.aspx (serveurs Windows)
Il s'agit du cas le plus simple et le plus visible de contenu dupliqué, et la plupart des gens en sont conscients.
Ce type de duplication se produit généralement dans l'ensemble d'un site Web, donc si votre site rend à www.example.com et exemple.com, il rend probablement aussi à www.example.com/category et exemple.com/catégorie. Cela signifie que les doublons sont présents sur tout le site et qu'ils ont un impact significatif sur les performances organiques.
Solutions
- Redirection 301 (permanente)
- Élément de lien canonique
Sous-dossiers, sous-catégories et pages enfant
La plupart des sites Web utilisent une certaine forme de catégories et de sous-catégories pour aider les utilisateurs à trouver des informations. Les catégories sont souvent les zones les plus importantes d'un site de commerce électronique, car elles ciblent intuitivement des termes de recherche spécifiques et raffinés. Par exemple, si je vends des gadgets sur Widgets.com, et qu'un client potentiel souhaite acheter des “gadgets bleus”, le plus souvent, c'est une page de catégorie pour “gadgets bleus” qui sera renvoyée comme résultat. Il en va de même pour tout site qui catégorise le contenu en sous-dossiers et en pages enfant.
Disons que la structure de mes catégories est la suivante :
exemple.com/category/sub-category
Ici, l'utilisateur a probablement navigué vers la première catégorie, puis vers l'une de ses sous-catégories. De nombreux systèmes permettent à cette sous-catégorie d'être rendue à l'adresse exemple.com/sub-category sans que la catégorie mère soit incluse dans l'URL. Cette sous-catégorie rend maintenant le même contenu sur plusieurs URL ; une qui inclut la catégorie parente, et une autre qui ne l'inclut pas.
Il en va de même pour les pages enfant qui peuvent être rendues sur exemple.com/category/product et exemple.com/product. Cela peut se produire sur un site non commercial comme exemple.com/services/nom-du-service et exemple.com/service-name.
Solution
- Redirection 301 (permanente)
- Élément de lien canonique
Pagination
Dans certains cas, le contenu d'une page de catégorie peut être divisé en plusieurs pages ; 1, 2 et 3, par exemple. Nous appelons cela une “série paginée”.
En reprenant l'exemple précédent, voici à quoi ressemblera normalement la page 1 :
exemple.com/categorie
La page 2 sera alors accessible à l'adresse suivante : exemple.com/category/?p=2
La façon dont la pagination est reflétée dans l'URL dépend de la configuration du site. Dans ce cas, nous sommes toujours dans la même catégorie, mais sur la deuxième page. Les moteurs de recherche pourraient bien interpréter les pages suivantes comme des doublons de la page 1.
Solution :
- éléments de lien rel=”next” et rel=”previous”.
Les paramètres
La plupart des sites Web ajoutent un paramètre à une URL en fonction de certaines conditions, comme l'utilisation d'un filtre, d'une fonction “trier par” ou d'une variété d'autres objectifs. Une cause courante est l'utilisation de “miettes de pain” qui aident les utilisateurs à naviguer sur un site. Les fils d'Ariane représentent le chemin que l'utilisateur a emprunté pour atteindre une page spécifique, et sont généralement cliquables à des fins de navigation.
Les fils d'Ariane sont spécifiques à l'utilisateur et sont pilotés par des paramètres de session qui sont parfois visibles dans l'URL de la page.
Par exemple
exemple.com/category/sub-category/product/?Path=312&214
Ici, “Path” fait référence au chemin emprunté par l'utilisateur, et les chiffres représentent des catégories spécifiques. Dans cet exemple, l'utilisateur a accédé à la catégorie 312, puis à la catégorie 214. Cela peut générer des fils d'Ariane qui ressemblent à ceci :
accueil -> catégorie -> sous-catégorie -> produit.
Nous nous trouvons toujours sur la même page de produit identifiée dans l'URL, mais avec des paramètres d'URL qui créent les fils d'Ariane.
Le même contenu est affiché sur cette page, mais on peut y accéder en utilisant différentes URL. Ce problème est exacerbé par le nombre de routes différentes qu'un utilisateur peut emprunter, ce qui augmente considérablement le nombre de doublons.
Solution
- Élément de lien canonique
Majuscules et barres obliques de fin de ligne
Certaines plates-formes ont tendance à ignorer les majuscules dans les URL, ce qui permet d'afficher une page indépendamment de la capitalisation. Si la page est accessible à partir d'URL qui contiennent des majuscules et d'autres qui n'utilisent que des minuscules, vous allez probablement rencontrer des problèmes. Par exemple
- exemple.com/categorie
- exemple.com/categorie
Il en va de même pour les barres obliques de fin de ligne (/) dans les URL :
- exemple.com/category
- exemple.com/category/
Solution
- Redirection 301 (permanente)
- Élément de lien canonique
Junk CMS aléatoire
Il ne s'agit évidemment pas d'un terme technique. Tous les sites Web ne fonctionnent pas sur la plateforme CMS la plus récente et la plus à jour. Beaucoup d'entre eux sont dépassés, faits sur mesure et, franchement, ne sont pas en bon état pour le référencement.
La qualité d'un CMS sur mesure, par exemple, est directement liée aux connaissances et aux capacités de l'équipe de développement qui l'a construit. Un léger manque de connaissances techniques en matière de référencement peut se traduire par un site qui produit une grande quantité de contenu dynamique dupliqué.
La recherche de ce type de contenu est assez simple : effectuez une recherche de site dans Google en utilisant “site:exemple.com”. Recherchez les URL indexées contenant des ” ?”, des paramètres de chemin, “index.php/ ?”. En supposant que vos URL sont adaptées au référencement, il s'agit très probablement de doublons non gérés de pages canoniques.
Solution
- Élément de lien canonique
Localisation et traduction
Il existe deux façons d'adapter le contenu à un public. La localisation consiste à fournir le contenu dans la même langue, mais les informations sont adaptées à chaque public pour tenir compte des différences linguistiques. Ces variantes peuvent exister sur un sous-domaine (us.example.com) ou un sous-dossier (example.com/us).
Lorsque des pages équivalentes existent pour une autre localité (comme uk.example.com ou example.com/uk), le contenu doit être localisé pour deux raisons
- s'assurer que le bon contenu est classé pour le bon public
- pour s'assurer qu'un contenu similaire n'est pas considéré comme un duplicata.
Il en va de même pour la traduction, sauf que la différence se situe au niveau de la langue. Par exemple, fr.exemple.com ou exemple.com/fr.
L'important est que les moteurs de recherche ne perçoivent pas ces pages comme des doublons non gérés, ou comme des pages différentes ; il s'agit de la même page, adaptée à un public différent.
Solution
- Je traiterai ce point dans un prochain article.
Autres cas de contenu dupliqué
Le contenu dupliqué peut se présenter sous d'autres formes. Une fois que vous avez compris de quoi il s'agit, vous pouvez identifier et résoudre les problèmes de duplication. Rappelez-vous que “le contenu dupliqué se produit lorsque la même page est rendue à plusieurs URL”.
Comment gérer le contenu dupliqué ?
Tout d'abord, le contenu dupliqué n'est pas une mauvaise chose – presque tous les sites Web produisent du contenu dupliqué. Le problème est que ce contenu n'est pas géré à l'aide de redirections 301, de directives robot, d'éléments de liens canoniques ou d'éléments de liens alternatifs.
Redirections 301 (permanentes)
Jusqu'à l'introduction de l'élément de lien canonique, les redirections 301 étaient le meilleur moyen de gérer le contenu dupliqué. Cependant, les éléments de redirection et de lien fonctionnent différemment.
Une fois qu'une redirection 301 est appliquée à un contenu dupliqué, l'utilisateur ne pourra plus y accéder et sera redirigé vers (tout va bien) la version canonique (correcte). Le problème est que souvent les doublons existent précisément pour les utilisateurs. Pour reprendre l'exemple des paramètres de chemin, les fils d'Ariane offrent une grande facilité d'utilisation aux visiteurs. Si les URL comprenant les paramètres de chemin sont redirigées, les fils d'Ariane ne fonctionneront plus correctement, ce qui nuira à la navigation sur le site.
Une 301 ne devrait être appliquée qu'aux pages qui n'offrent aucune valeur ajoutée à l'utilisateur, comme le domaine racine et le sous-domaine (www.example.com et example.com). Ce faisant, environ 90 % de l'autorité de la page donneuse vers la page cible de la redirection est maintenue, ce qui consolide votre capital de liens.
Éléments de liens canoniques
L'élément de lien canonique traite le contenu dupliqué de la même manière qu'une redirection 301, à une exception près : les utilisateurs peuvent toujours accéder à la page. Il s'agit donc du moyen le plus efficace de gérer les doublons sans risquer de nuire à l'expérience des utilisateurs.
Un élément de lien canonique ressemble à ceci :
<link rel=”canonical” href=”http://example.com”>
Il pointe vers la version canonique (correcte) de la page Web sur laquelle il se trouve. La beauté de l'élément de lien canonique est qu'il peut être appliqué à l'ensemble du site, assurant une protection contre les problèmes de contenu dupliqué, qu'il y ait un problème ou non.
La version canonique de la page doit comporter un élément de lien canonique autoréférent, c'est-à-dire un lien qui pointe vers lui-même. Par conséquent, tous les doublons de cette page auront un élément de lien canonique pointant vers la version canonique.
Comme une redirection 301, l'élément de lien canonique transmet environ 90 à 95 % de la valeur du lien à la page cible. Les éléments de liens canoniques fonctionnent également entre les domaines. Ainsi, si pour une raison quelconque, votre site est rendu sur un deuxième domaine, les éléments de liens canoniques renverront toujours à l'original, évitant ainsi les problèmes de duplication.
Un dernier conseil
Il existe quelques nuances pour tirer le meilleur parti d'un élément de lien canonique et pour choisir la version canonique. La version définie comme canonique sera classée dans les moteurs de recherche. Il faut donc utiliser celle qui a le plus de chances d'être bien classée.
Par exemple, je peux avoir une page de produit qui est rendue à l'adresse exemple.com/mens-shoes/black-shoes et aussi à l'adresse exemple.com/black-shoes. Si quelqu'un cherche “chaussures noires pour hommes”, lequel de ces sites a le plus de chances d'être classé ? Lorsque la catégorie ou la sous-catégorie contient des termes de recherche importants, il peut être intéressant de définir la version canonique comme étant celle qui les inclut dans l'URL.
Vous avez peut-être remarqué l'apparition de “miettes de pain structurées” à un moment donné en 2013, ou peut-être pas. Traditionnellement, lorsqu'une page Web apparaît dans les SERP, l'URL de la page s'affiche sous le titre de la page.
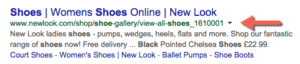
Avec le bon code en place, il est maintenant possible d'afficher l'architecture réelle du site, sur la base des fils d'Ariane.

Si l'on se réfère à mon exemple précédent de catégories, de sous-catégories et de pages enfant, pour que ces éléments magnifiquement structurés s'affichent, les versions canoniques des sous-catégories DOIVENT inclure les catégories parentes dans l'URL afin que la version canonique comprenne le fil d'Ariane correct.
Robots.txt
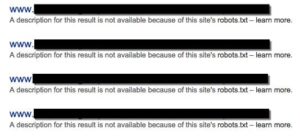
Ni le contenu dupliqué, ni l'indexation ne doivent être gérés à l'aide du fichier robots.txt. Une entrée disallow dans Robots.txt fournit des métadirectives au niveau du domaine racine et il est très fréquent que les pages désavouées dans Robots.txt continuent à être indexées lorsqu'elles sont accédées directement par Googlebot ou un autre robot d'exploration. Une fois qu'une page interdite est indexée, elle reste dans l'index indépendamment du contenu de votre fichier robots.txt et empêche également les robots d'indexation de détecter les éléments de liens canoniques sur les pages en question. Jetez un coup d'œil ci-dessous :
Si vous insistez pour essayer de gérer le contenu dupliqué en contrôlant l'indexation, il est préférable d'utiliser la directive méta “noindex” au niveau de la page – une solution beaucoup plus fiable. Cependant, cela ne transmettra pas d'autorité de lien aux pages canoniques comme le ferait un élément de lien canonique ou une redirection 301.
Bien… des questions ?
Avec 2400 mots, il y a encore beaucoup de choses que j'aimerais écrire sur le sujet, et je le ferai peut-être. Si après avoir lu ceci vous ne savez toujours pas ce qu'est le contenu dupliqué, n'hésitez pas à demander de l'aide dans les commentaires ci-dessous.