
Sommaire
- 1- Les Erreurs SEO stupides #1 : dire à son CMS de ne pas indexer son site
- 2- Erreurs SEO stupides #2 : ne pas vérifier la qualité de son code dans le validateur W3C
- 3- Erreurs SEO stupides #3 : oublier de passer les liens externes en NoFollow et perdre le jus SEO
- 4- Les Erreurs SEO stupides #4 : Oublier de travailler son fichier robots.txt
- 5- Oublier de désindexer son site de pre-prod
- 6- Erreur SEO fréquente #6 : la mauvaise gestion de la balise rel=canonical
- 7- Erreurs SEO stupides #7 : Commander des backlinks pour $5 sur fiverr et le regretter plus tard
- 8- Erreurs SEO stupides #8 : Ne pas utiliser Search Console de Google
- 9- Erreur SEO #9 : Faire une refonte de son site et oublier les redirections 301 (ou tout faire pointer vers la page d’accueil)
- 10- Erreur SEO : générer du duplicate content
- 11 – Update 2020 : oublier de corriger les erreurs répertoriées par la GSC
- Les meilleurs articles SEO à propos des erreurs de noob
- Quand Matt Cutts (à l'époque chez Big G) liste les pires erreurs SEO aux yeux de Google
- Les pires erreurs SEO : update 2022
- Faites ces erreurs pour améliorer votre statut HTTP
- Sous-optimisation des balises méta
- Voici les 5 erreurs de métabalises les plus courantes qui peuvent nuire à vos classements
- Créer du contenu dupliqué
- Voici les problèmes de duplication les plus courants qui nous freinent :
- Les problèmes de liens les plus courants qui peuvent avoir un impact sur vos classements :
On est tête en l’air ou on ne sait tout simplement pas… alors voilà une liste de erreurs SEO fréquentes et mineures à ne pas oublier quand on fait du SEO ou que l’on gère un site. Des erreurs SEO mineures mais qui ont de grosses conséquences sur votre positionnement dans les résultats de recherche des moteurs, Google en tête. Croyez-moi, ces erreurs SEO mineurs ont parfois des conséquences énormes sur votre référencement naturel et pourrez amener les robots crwler à ne pas indexer votre site.
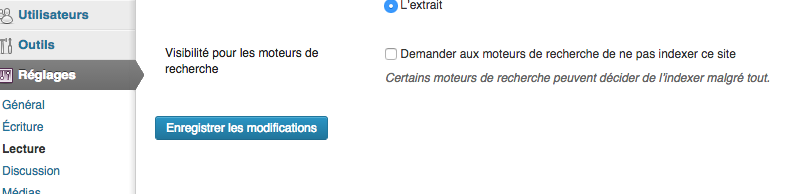
1- Les Erreurs SEO stupides #1 : dire à son CMS de ne pas indexer son site
Quand on utilise un CMS, on a une multitude d’options à cocher, décocher, modifier… qui influencent le référencement de votre site web. Il y a une option qui fait que votre site web ne sera JAMAIS indexé par les moteurs de recherche. C’est l’option qui vous permet de demander aux moteurs de recherche de ne pas indexer votre site. Oui, oui, quand vous réalisez que vous avez coché cette option SEO dans WordPress lors de l’installation, vous vous sentez bête.
2- Erreurs SEO stupides #2 : ne pas vérifier la qualité de son code dans le validateur W3C
Vous devez le savoir, mais tout ce qui est sur internet est fait de code. Le code a ses règles et les moteurs de recherche aiment quand elles sont respectées. Si votre site ne respecte pas une structure précise, possiblement validée par l’instance W3C, votre référencement SEO risque d’être mis à mal… Notre conseil : rester DRY (Don’t Repeat Yourself) si vous modifier votre thème ou le cœur de votre CMS et tester encore et encore votre site web sur le testeur W3C (HTML). Ça vous évitera cette erreur SEO.
3- Erreurs SEO stupides #3 : oublier de passer les liens externes en NoFollow et perdre le jus SEO
Ne pas passer les liens externes de votre sites en nofollow est une erreur SEO qui peut vous coûter cher. Tous les spécialistes du SEO vous le diront, si vous prenez la peine de créer un site et de travailler votre référencement naturel (création de liens, optimisation On/Off Page…), ne ruinez pas tout en laissant les liens sur votre site en DoFollow! En effet, une fois que les robots sont sur votre site : gardez-les ! En passant les liens externes présents dans vos articles en NoFollow, les robots verront le lien, comprendront la démarche, mais ne sortiront pas de votre site et continueront leur visite !
Voilà à quoi ressemble un lien en NoFollow sur internet <a href=”/monlien/” rel=”nofollow”>mon ancre</a> et voilà ce que dit Google à propos du NoFollow.
4- Les Erreurs SEO stupides #4 : Oublier de travailler son fichier robots.txt
Pour la faire vite : le fichier robots.txt se trouve à la racine de votre site internet, c’est le premier fichier que les robots (Google, Google images, Bing…) vont lire en arrivant sur votre site. Ce fichier robtos.txt permet de prioriser ou de restreindre leur travail. En regardant ce fichier, ils sauront s’ils ont le droit ou non de crawler tel page, tel dossier, tel fichier… En SEO, si vous laissez votre robots.txt comme à l’initial, il ressemblera à cela :
User-Agent : *
Allow : /
Si on traduit ce bout de code, çela signifie que tous les robots (*=tout, User-Agent = robots) ont le droit de crawler toutes les pages (Allow=autorisé et /=tous les dossiers de votre serveur). Imaginez l’erreur SEO ! En effet, l’objectif en SEO est de ne pas fatiguer les robots, pour qu’ils comprennent qu’on prend soin d’eu et qu’ils reviennent le plus souvent possible crawler votre site. Si le robot perd du temps, les serveurs de Google/Bing/Yahoo perdent du temps, donc de l’argent, donc il n’enverra plus ses robots sur votre site. Donc si vous autorisez tous les dossiers au crawl, vous donnerez à manger des pages et des fichiers inutiles aux robots, ex. : les fichiers de configuration de WordPress, les fichiers JavaScript… Donc empressez-vous de retoucher votre robots.txt pour éviter de fatiguer les robots et les faire revenir le plus souvent possible.
5- Oublier de désindexer son site de pre-prod
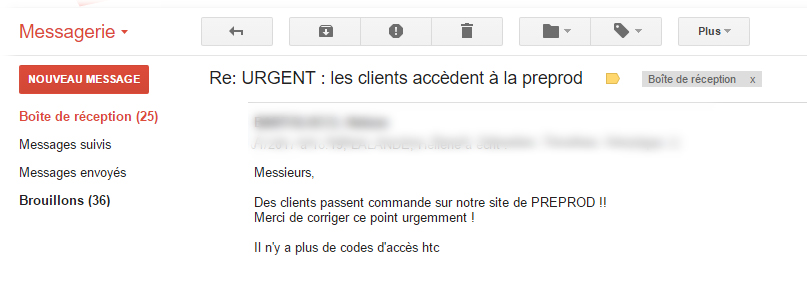
Avant hier, quand j'ai ouvert mes mails et que j'ai vu un objet “URGENT : NOS CLIENTS ACCÈDENT À LA PRE-PROD” j'ai un peu rigolé (ce n'est pas moi qui code le site) et puis je me suis dit : branle-bas de combat, que s'est-il passé ? Réponse : la gentille agence de développement avait cassé le Htaccess et le HTPassword du site de pre-prod et les robots de google avait commencé à indexer le site. Résultat : 1853 pages indexées dans les résultats de recherche. Donc l'erreur était de ne pas mettre de “Disallow: *” dans le robots.txt à la racine du domaine de pre-prod et/ou une meta : robots=”Noindex” dans le header des pages et/ou mettre un password via le HTAccess/Htpwd.
6- Erreur SEO fréquente #6 : la mauvaise gestion de la balise rel=canonical
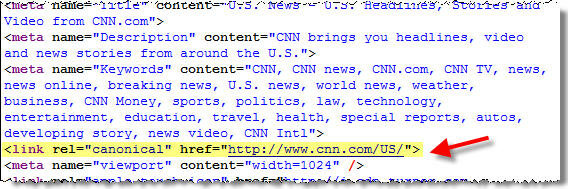
Exemple véridique d’un client e-commerce qui voulait absolument travailler avec un CMS développé en interne, et qui s’est retrouvé avec des déclinaisons (avis, fiche technique..) et des balises rel=canonical renvoyant vers la page courante. Donc pour faire simple 10 pages identiques pour un seul produit.
Romain – Agence Pandaa !
7- Erreurs SEO stupides #7 : Commander des backlinks pour $5 sur fiverr et le regretter plus tard
Même quand t'es growth hacker, si tu veux que ton site monte vite dans les résultats de recherche, il faut garder la tête sur les épaules et bien choisir ses backlinks. Fiverr, la plateforme de services à 5$, propose de nombreuses possiblités pour créer des backlinks rapidement. Ces backlinks pas chers ne sont pas la bonne solution ! Méfiez-vous ! Ils vous desserviront dans le futur, car ils sont faits sur des sites de mauvaise qualité.
Camille Besse, fondateur de growthhacking.fr, sur Twitter : @CamilleBesse
8- Erreurs SEO stupides #8 : Ne pas utiliser Search Console de Google
Si tous les webmaster connaissent Search Console, ils ne l’utilisent pas tous et c’est une erreur qui peut avoir des conséquences graves ! En effet on y trouve de précieux conseils concernant l’indexation de son site, la vitesse de crawl, son optimisation, etc… mais on y trouve surtout … les avertissements en cas de pénalité ! Et oui, quand le trafic d’un site chute, il faut avoir le réflexe de regarder dans la Search Console, vous y trouverez peut-être la raison sous forme d’avertissement. A vous de corriger le tir.. si c’est le cas… et d'éviter cette erreur SEO un peu stupide.
9- Erreur SEO #9 : Faire une refonte de son site et oublier les redirections 301 (ou tout faire pointer vers la page d’accueil)
Ca y est, le nouveau site est près ! Mais avant de le mettre en ligne, avez-vous prévu votre fichier de redirections 301 ? Ok, si le site possède plusieurs milliers de pages, cela peut paraître fastidieux. Mais c’est indispensable ! Et attention, il faut rediriger page à page… sous peine de voir le site perdre une part importante de son trafic. Que l’utilisateur arrive sur une 404 pour cause de changement d’url sans redirection ou qu’il aboutisse sur la page d’accueil, ces petites paresses pourraient vous coûter cher. Alors, on se retrousse les manches et on fait son plan de redirections !
Capture d’écran réelle, devinez quand a eu lieu la refonte et l’oubli des 301 ?
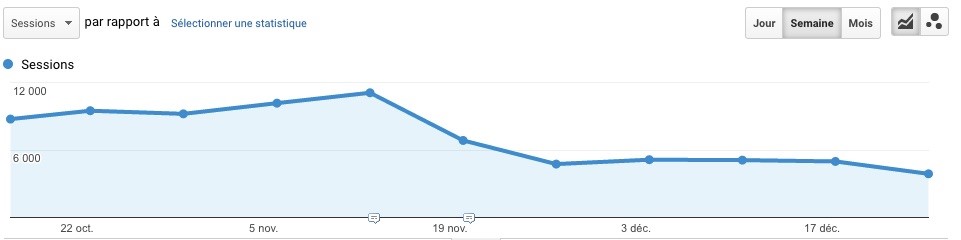
Les erreurs 8 et 9 nous ont eté suggérées par Marie Pourreyron, son blog www.mar1e.fr vous aidera en SEO.
10- Erreur SEO : générer du duplicate content
Thomas de chez Artkeos nous dit, à propos des erreurs SEO en rapport au contenu dupliqué :
Dans le genre « Erreurs de noob » j’en ai vue pas mal en arrivant à mon poste actuel… Par exemple, reprendre la description de l’entreprise de la page d’accueil et la poster sur tous les réseaux sociaux, job board, etc. En gros le meilleur moyen de générer du duplicate content de son propre site….
Je pense aussi au stagiaire ayant besoin de créer du contenu. N’ayant pas de temps il reprend donc des articles ici et là pour alimenter le blog de l’entreprise. Ceci générant encore du duplicate content.
11 – Update 2020 : oublier de corriger les erreurs répertoriées par la GSC
La plupart de nos clients, quand ils commencent une prestation SEO avec Punchify, n'ont pas ou n'utilisent que peu les données fournies par la Google Search Console. Ces données sont pourtant précieuses ! En effet, les erreurs répertoriées par Google lors de ses crawls sont tout simplement une liste de choses à fixer le plus vite possible sur le site. Google perd du temps lors de son crawl et perd de l'argent quand il fait face à ces erreurs. Par conséquent, en corrigeant ces erreurs Google favorisera notre site dans les SERPs.
Exemple typique d'erreur SEO en lien avec les metadata d'un site sur lequel nous constations une baisse de l'augmentation des visites :
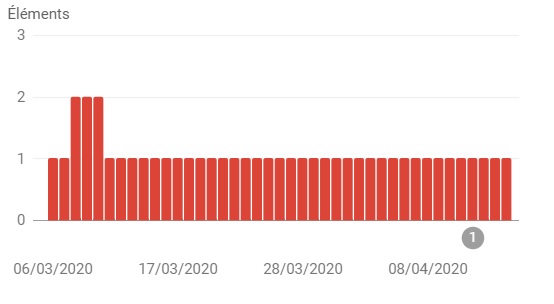
Les meilleurs articles SEO à propos des erreurs de noob
Quand Miss-SEO-girl nous parle des erreurs de noob en SEO
Alexandra Martin nous présente sa vision des erreurs SEO dans un article de blog qui reprend bon nombre des erreurs mentionnées ci-dessus. Néanmoins, il y a d'autres petites idées que nous n'avons pas mentionné et qui sont des erreurs SEO de base (oublier les Alt aux images, ne pas avoir de page 404…). Et comme son article avait été rédigé en Novembre 2015, elle évoque même les sites développés en Flash. Lol. Consultez son article : Les principales erreurs SEO à éviter pour un meilleur référencement.
Lorsque Fabien Kulber s'y met
Fabien Kulber nous parle un peu moins des erreurs techniques que l'on peut faire lorsque l'n travaille le référencement naturel de son site, mais plus des erreurs sur la manière dont les gens pensesnt le SEO : c'est gratuit, ça marche vite… Lisez son article si vous n'êtes pas encore très avancé ou que vous pensez que vous pouvez faire votre SEO tout seul. Son article est : 7 erreurs SEO fréquentes et facilement évitables.
Quand Matt Cutts (à l'époque chez Big G) liste les pires erreurs SEO aux yeux de Google
Matt Cuts donne une liste d'erreurs SEO qui sont les plus importantes aux yeux de Google et qui sont très communes sur les sites internet. Voilà la vidéo qu'il avait fait en 2013 (oui oui, 2013 !), mais la plupart des erreurs listées sont encore d'actualité.
Voilà les erreurs SEO fréquentes et simple à éviter qui pourraient affecter votre SEO. Si vous pensez que tout cela est bien en place sur votre site mais que votre référencement naturel est toujours un mystère de polichinelle, nous vous invitons à nous contacter pour un audit SEO gratuit ou une prestation SEO à Paris et en province.

Vous êtes une agence SEO, freelance SEO ou entrepreneur et vous avez de l'expérience en terme d'erreurs SEO stupides qui ont un gros impact sur le référencement de votre site ? Partagez vos retours dans les commentaires et nous ajouterons les meilleurs dans l'article ! Merci
Les pires erreurs SEO : update 2022
Les webmasters doivent se battre pour les problèmes techniques de leur site et suivre les mises à jour constantes.
Même si vous connaissez certains problèmes de votre site, il peut être difficile de le maintenir en bonne santé dans le monde en constante évolution du référencement.
Vous pouvez réduire les problèmes techniques et améliorer les performances de votre site en étant conscient des erreurs les plus courantes (potentiellement dangereuses).
Cette liste de contrôle vous donnera une liste de contrôle complète d'audit de site pour vous aider en tant que webmaster.
Vous ignorez le statut HTTP et les problèmes de serveur
La plupart des problèmes techniques les plus importants d'un site Web sont liés à son statut HTTP.
Ces codes incluent l'erreur 404 (Page Not Found), qui indique la réponse du serveur à la demande d'un client, tel qu'un navigateur ou un moteur de recherche.
La confiance qu'un utilisateur accorde à votre site est affectée lorsque le dialogue entre un client (ou un serveur) est interrompu ou brisé.
Les problèmes graves de serveur peuvent non seulement entraîner une perte de trafic en raison de l'inaccessibilité du contenu, mais aussi nuire à votre classement si Google n'est pas en mesure de trouver les bons résultats pour le chercheur.
Faites ces erreurs pour améliorer votre statut HTTP
1. Erreurs 4xx
Une page dont l'état est 4xx ne peut être atteinte, ce qui signifie qu'elle est en panne. Ces codes peuvent également être appliqués à des pages qui sont toujours accessibles mais bloquées par quelque chose.
2. Pages non explorées
Cela se produit lorsqu'une page n'est pas accessible pour l'une des raisons suivantes : 1. Le temps de réponse de votre site est supérieur à cinq secondes ou 2. Votre serveur refuse l'accès à la page.
3. Liens internes brisés
Ces liens mènent à des pages non fonctionnelles, ce qui peut entraîner des problèmes de référencement et d'ergonomie.
4. Liens externes brisés
Ces liens conduisent les utilisateurs vers des pages qui n'existent pas ailleurs, ce qui constitue un signal négatif pour les moteurs de recherche.
5. Images internes cassées
Cet indicateur est utilisé lorsqu'un fichier est manquant ou introuvable.
Une autre erreur courante dans le statut HTTP est :
Redirections permanentes
Redirections temporaires
Sous-optimisation des balises méta
Vos balises méta aident les moteurs de recherche à identifier les sujets de vos pages pour les relier aux mots-clés et aux expressions utilisés par les chercheurs.
Pour créer des balises de titre correctes, il faut choisir des mots clés pertinents afin de créer un lien unique, digne d'être cliqué, que les utilisateurs peuvent utiliser dans les pages de résultats des moteurs de recherche (SERP).
Les méta-descriptions vous offrent davantage de possibilités d'inclure des mots-clés ou des expressions connexes.
Elles doivent être uniques et aussi personnalisées que possible. Google les génère automatiquement à partir des mots clés saisis par les utilisateurs. Cela peut parfois conduire à des termes de recherche ou à des résultats associés qui ne correspondent pas.
Les titres et métadonnées optimisés doivent inclure les mots clés les plus pertinents, être de la bonne longueur et éviter autant que possible les doublons.
Le commerce électronique de mode est un exemple de secteur qui ne peut pas créer de descriptions uniques pour chaque produit. Par conséquent, les pages de destination doivent offrir une valeur unique dans les autres domaines.
Pour maximiser l'impact de votre site sur les SERP, il vaut la peine d'envisager des métadonnées uniques si elles sont possibles.
Voici les 5 erreurs de métabalises les plus courantes qui peuvent nuire à vos classements
6. Des méta-descriptions et des balises de titre qui sont dupliquées
Les moteurs de recherche ont du mal à déterminer la pertinence et le classement de plusieurs pages dont les titres et les descriptions sont identiques.
7. Il vous manque des balises H1
Les moteurs de recherche utilisent les balises H1 pour déterminer le sujet de votre contenu. Google ne comprendra pas votre site Web si elles sont absentes.
8. Il manque des méta-descriptions
Google comprendra votre pertinence et incitera les utilisateurs à cliquer sur votre résultat si les méta-descriptions sont bien rédigées. Les taux de clics peuvent chuter si elles ne sont pas incluses.
9. Il vous manque les attributs ALT
Les moteurs de recherche et les malvoyants peuvent utiliser les attributs ALT pour décrire les images de votre contenu. Ils sont essentiels pour l'engagement et la préservation de la pertinence.
10. Balises H1 et balises de titre en double
L'optimisation peut être excessive si les balises H1 et les balises de titre d'une page sont identiques. Cela peut conduire à des opportunités de classement pour des mots-clés pertinents.
Créer du contenu dupliqué
Le contenu dupliqué peut nuire à votre classement, et peut-être pour un certain temps.
La duplication du contenu d'autres sites est une mauvaise idée, qu'il s'agisse d'un concurrent direct ou non.
Faites attention aux descriptions, paragraphes et sections entières de texte dupliqués, aux balises H1 dupliquées sur plusieurs pages Web et aux problèmes d'URL tels que les versions www et not-www de la page.
Pour s'assurer qu'une page est cliquable par les utilisateurs, Google ne se contente pas de prendre en compte le caractère unique de chaque détail, mais le classe également dans les résultats de recherche de Google.
Voici les problèmes de duplication les plus courants qui nous freinent :
11. Contenu dupliqué
Les outils d'audit de site signalent le contenu dupliqué si des pages de votre site Web partagent la même URL ou la même copie. Vous pouvez résoudre ce problème en ajoutant un hyperlien ref=”canonical” à l'une des pages dupliquées ou en utilisant une redirection.
Les autres erreurs de duplication courantes sont les suivantes :
- Balises H1 et balises de titre dupliquées
- Duplication des méta-descriptions
- Négliger l'optimisation des liens internes et externes
Votre expérience utilisateur peut être affectée par les liens que vous fournissez à vos clients. Cela peut avoir un impact sur les performances de votre moteur de recherche et sur votre expérience utilisateur. Google ne classera pas les sites Web qui offrent une mauvaise expérience utilisateur.
L'outil Site Audit a révélé que près de la moitié des sites analysés présentaient des problèmes de liens externes et internes. Cela indique que les architectures de liens individuelles du site ne sont peut-être pas optimisées.
Les liens dont l'URL comporte un trait de soulignement contiennent des attributs nofollow et sont en HTTP au lieu de HTTPS. Cela peut affecter les classements.
Site Audit peut vous aider à trouver les liens brisés. Ensuite, identifiez ceux qui ont le plus d'impact sur l'engagement des utilisateurs et réparez-les dans l'ordre où ils sont les plus importants.
Les problèmes de liens les plus courants qui peuvent avoir un impact sur vos classements :
12. Liens vers des pages HTTP à partir d'un site Web HTTPS
Les anciennes pages HTTP peuvent provoquer un dialogue non sécurisé entre les utilisateurs et les serveurs. Assurez-vous que tous vos liens sont à jour.
13. URL contenant des traits de soulignement
Les moteurs de recherche pourraient mal comprendre les traits de soulignement et documenter incorrectement l'index de votre site. Utilisez plutôt des traits d'union.
Une autre erreur courante dans la création de liens :
Les liens internes brisés
Les liens externes brisés
Les liens externes ne doivent pas contenir d'attributs nofollow
Un seul lien interne est autorisé sur les pages
La profondeur d'exploration des pages doit être supérieure à 3 clics.
Voici ma petite contribution aux erreurs stupides : La mauvaise gestion de la balise rel=canonical Exemple véridique d’un client e-commerce…
Voilà, Voilà Bisous
Merci Romain !
Article mis à jour avec ta contribution.
Clément
Bonjour,
-Oublier le sitemap.xml
-Ne pas mettre de texte alternatif sur les images du site
-Oublier de mettre un filtre Ip sur sa propre IP dans Google Analytics,e t donc se retrouver avec des visites complétement fausse (ça marche aussi avec le trafic des Bots…)
-Etc.
Je dois en oublier, mais il y a tellement d’erreurs qu’on fait quand on commence en référencement…
Merci Thomas, j’ai coupé ton commentaire et j’en ai ajouté un bout dans l’article en citant ton nom 😉 Je t’invite à en faire profiter les débutants en SEO autour de toi !
A+
Clément
Ne pas mettre de liens internes vers ses pages de contenu (blog etc.) (vu vu et revu !!! ) , Google ne les trouve jamais !